Unveiling Recurrent Neural Networks: The Backbone of Sequential Data Processing
Unveiling Recurrent Neural Networks: The Backbone of Sequential Data Processing
In the dynamic field of artificial intelligence, understanding how to handle sequential data—data where the order matters, such as time series or natural language—is crucial. Recurrent Neural Networks (RNNs) have been a cornerstone of this endeavor. Introduced in the 1980s, RNNs have undergone significant evolution, becoming the foundation for many applications in natural language processing (NLP), speech recognition, and beyond. Let’s explore what makes RNNs so essential and how they’ve paved the way for advanced AI models.
What are Recurrent Neural Networks?
Recurrent Neural Networks are a class of artificial neural networks designed to recognize patterns in sequences of data. Unlike traditional feedforward neural networks, which process inputs independently, RNNs have connections that form directed cycles, allowing them to maintain a ‘memory’ of previous inputs. This ability to retain information makes RNNs particularly effective for tasks where the context or order of inputs is important.
The Core Mechanism: Recurrent Connections
The defining feature of RNNs is their recurrent connections. At each time step, the network takes an input and the hidden state from the previous time step to produce an output and update the hidden state. Mathematically, this can be described as:
Here:
- ( h_t ) is the hidden state at time step ( t ).
- ( x_t ) is the input at time step ( t ).
- ( y_t ) is the output at time step ( t ).
- ( W_{xh} ), ( W_{hh} ), and ( W_{hy} ) are weight matrices.
- ( b_h ) and ( b_y ) are bias terms.
- ( \sigma ) is the activation function (often tanh or ReLU).
This mechanism enables the network to capture dependencies in the sequence of data, making RNNs powerful for tasks like language modeling and sequence prediction.
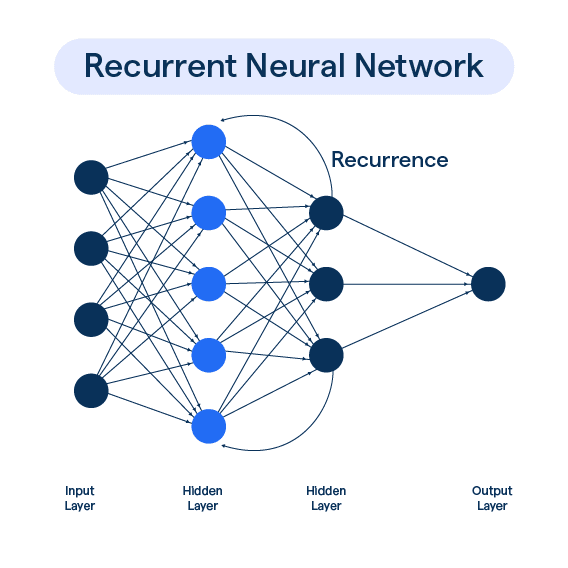
Recurrent Neural Network. (2022). BotPenguin. https://botpenguin.com/glossary/recurrent-neural-network
Variants of RNNs
While basic RNNs are conceptually simple, they struggle with learning long-range dependencies due to issues like the vanishing gradient problem. To address these limitations, several advanced variants have been developed:
Long Short-Term Memory (LSTM)
Introduced by Hochreiter and Schmidhuber in 1997, LSTMs incorporate memory cells and gates (input, output, and forget gates) to regulate the flow of information. This design helps LSTMs retain relevant information over longer sequences, making them highly effective for tasks such as machine translation and speech recognition.
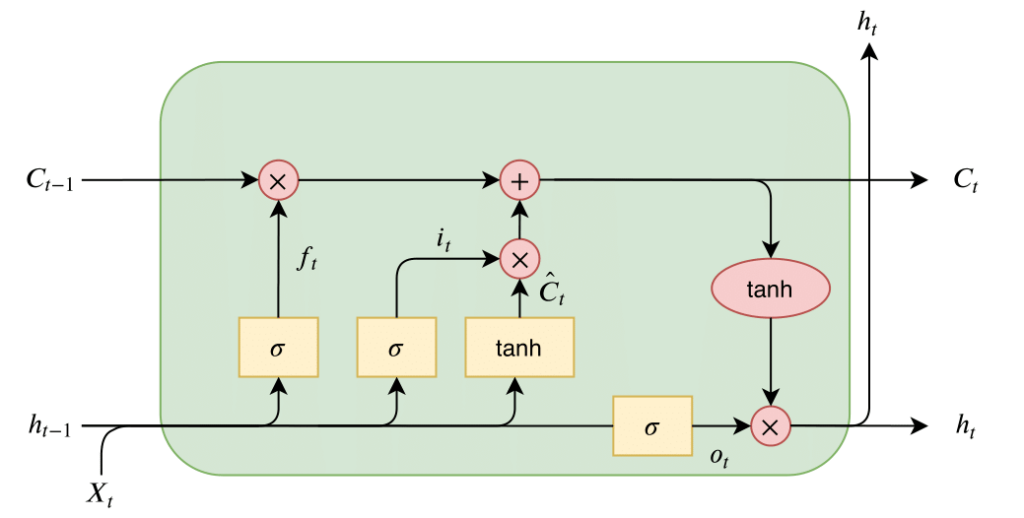
Saba Hesaraki. (2023, 27 de Octubre). Long Short-Term Memory (LSTM). https://medium.com/@saba99/long-short-term-memory-lstm-fffc5eaebfdc
Gated Recurrent Unit (GRU)
Proposed by Cho et al. in 2014, GRUs are a simplified version of LSTMs, using only two gates (reset and update gates). GRUs often perform similarly to LSTMs but with fewer parameters, making them more computationally efficient.
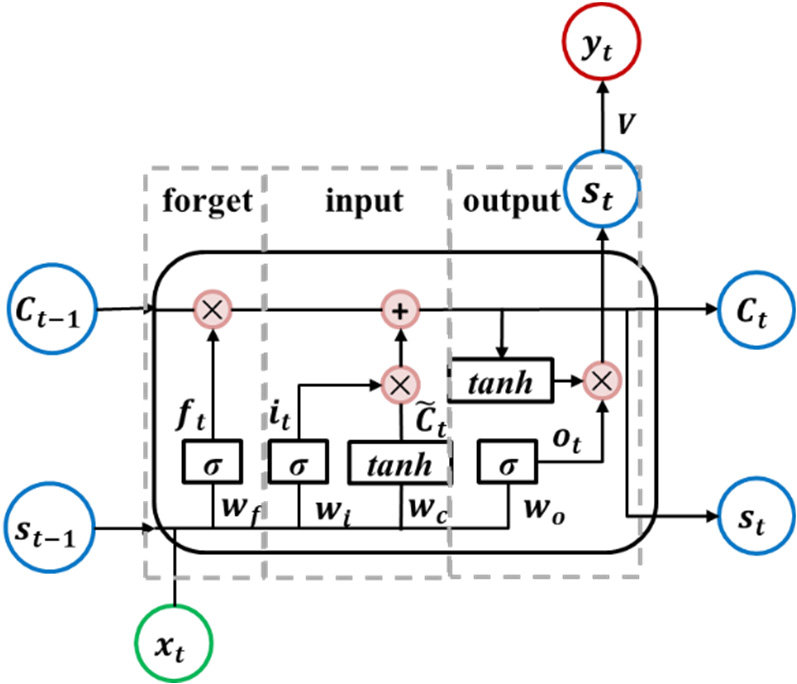
Evaluation of Three Deep Learning Models for Early Crop Classification Using Sentinel-1A Imagery Time Series-A Case Study in Zhanjiang, China – Scientific Figure on ResearchGate. Available from: https://www.researchgate.net/figure/Diagram-of-the-gated-recurrent-unit-RNN-GRU-RNN-unit-Diagram-of-the-gated-recurrent_fig1_337294106 [accessed 28 May, 2024]
Applications of RNNs
RNNs have been employed in a wide array of applications due to their ability to handle sequential data. Some notable applications include:
Natural Language Processing (NLP)
RNNs have been used extensively in NLP tasks such as language modeling, text generation, sentiment analysis, and machine translation. They can understand and generate text based on context, providing coherent and contextually relevant outputs.
Speech Recognition
In speech recognition, RNNs process audio signals to transcribe spoken language into text. They excel at capturing temporal dependencies in audio data, leading to significant improvements in transcription accuracy.
Time Series Prediction
RNNs are well-suited for predicting future values in time series data, such as stock prices, weather forecasting, and anomaly detection. Their ability to model temporal dependencies makes them effective for forecasting tasks.
Challenges and Limitations
Despite their strengths, RNNs come with certain challenges:
Vanishing and Exploding Gradients
During training, RNNs can suffer from vanishing or exploding gradients, where gradients become too small or too large, hindering the learning process. LSTMs and GRUs mitigate this issue to some extent, but it remains a fundamental challenge.
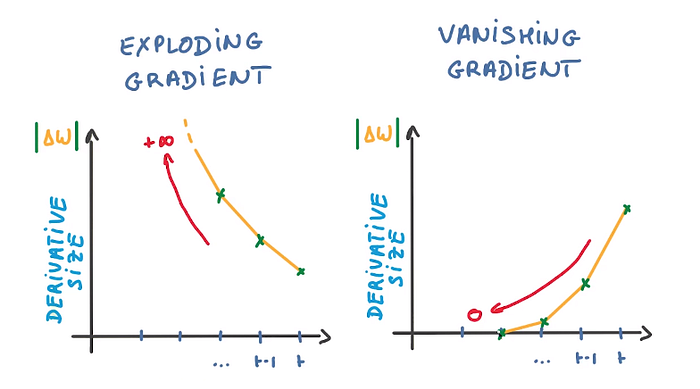
Nisha Arya Ahmed. (2022, 10 de noviembre). Vanishing/Exploding Gradients in Neural Networks. https://www.comet.com/site/blog/vanishing-exploding-gradients-in-deep-neural-networks/
Computational Inefficiency
RNNs process data sequentially, which limits parallelization and can lead to longer training times compared to models like Transformers that process entire sequences simultaneously.
Capturing Long-Range Dependencies
While LSTMs and GRUs improve the ability to capture long-range dependencies, they are not perfect and can still struggle with very long sequences.
Conclusion
Recurrent Neural Networks have played a pivotal role in advancing AI’s ability to understand and process sequential data. Despite the emergence of newer architectures like Transformers, RNNs and their variants like LSTMs and GRUs remain foundational tools in the AI toolkit. Their unique ability to maintain context over sequences has enabled significant progress in fields such as NLP, speech recognition, and time series analysis.
As we continue to explore the depths of AI, understanding the strengths and limitations of RNNs provides valuable insights into the evolution of neural networks and their applications. Stay tuned to our blog for more deep dives into the world of artificial intelligence and its transformative technologies.