Demystifying Transformer Architecture: Revolutionizing AI and NLP
In the rapidly evolving world of artificial intelligence, certain breakthroughs mark pivotal moments that propel the field into new realms of possibility. One such groundbreaking development is the Transformer architecture, introduced by Vaswani et al. in the seminal 2017 paper «Attention is All You Need.» This architecture has since become the backbone of many state-of-the-art models in natural language processing (NLP), including OpenAI’s GPT series and Google’s BERT. Let’s delve into what makes the Transformer architecture so transformative.
The Evolution of NLP Models
Before the advent of Transformers, NLP models primarily relied on recurrent neural networks (RNNs) and their more sophisticated cousins, long short-term memory networks (LSTMs) and gated recurrent units (GRUs). These architectures were adept at handling sequential data, making them suitable for tasks like language modeling and machine translation. However, they came with significant limitations:
- Sequential Processing: RNNs process tokens in sequence, which hampers parallelization and increases computational costs.
- Long-Range Dependencies: Capturing long-range dependencies in text was challenging, leading to difficulties in understanding context in lengthy sentences.
Enter the Transformer
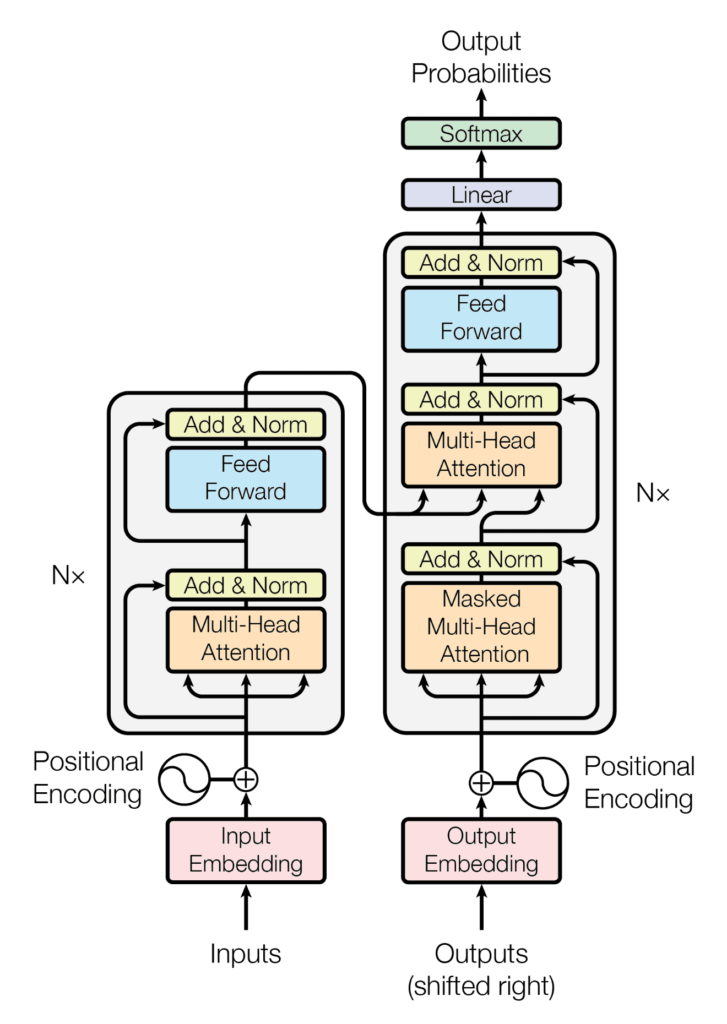
The Transformer architecture addresses these limitations through its novel use of self-attention mechanisms, enabling it to handle dependencies regardless of their distance in the input sequence. Here’s a closer look at its key components and innovations:
Vaswani, A., Shazeer, N., Parmar, N., Uszkoreit, J., Jones, L., Gomez, A. N., Kaiser, L., & Polosukhin, I. (2017). Attention Is All You Need (Versión 7). arXiv. https://doi.org/10.48550/ARXIV.1706.03762
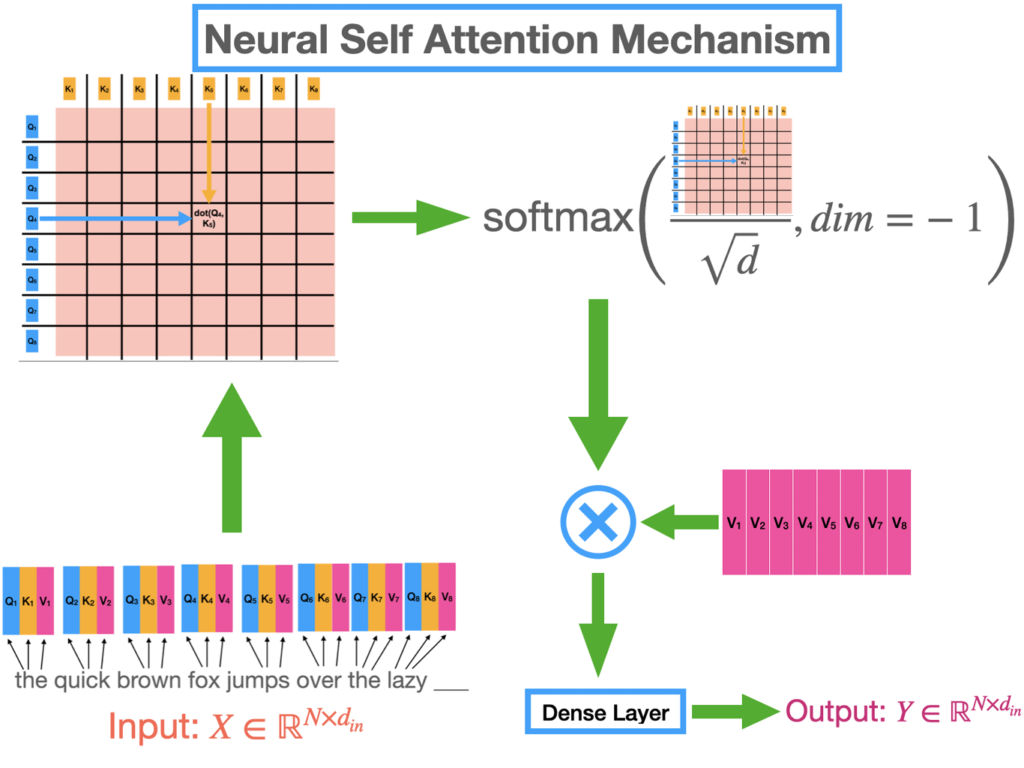
Self-Attention Mechanism
At the heart of the Transformer is the self-attention mechanism, which allows the model to weigh the importance of different words in a sentence when encoding a particular word. This mechanism computes three vectors for each word: Query (Q), Key (K), and Value (V). By calculating dot products between these vectors, the model determines how much focus to place on other words in the sequence when processing a specific word.
Jaiyan Sharma. (2023, 7 de febrero). Understanding Attention Mechansim in Transformer Neural Networks. https://learnopencv.com/attention-mechanism-in-transformer-neural-networks/
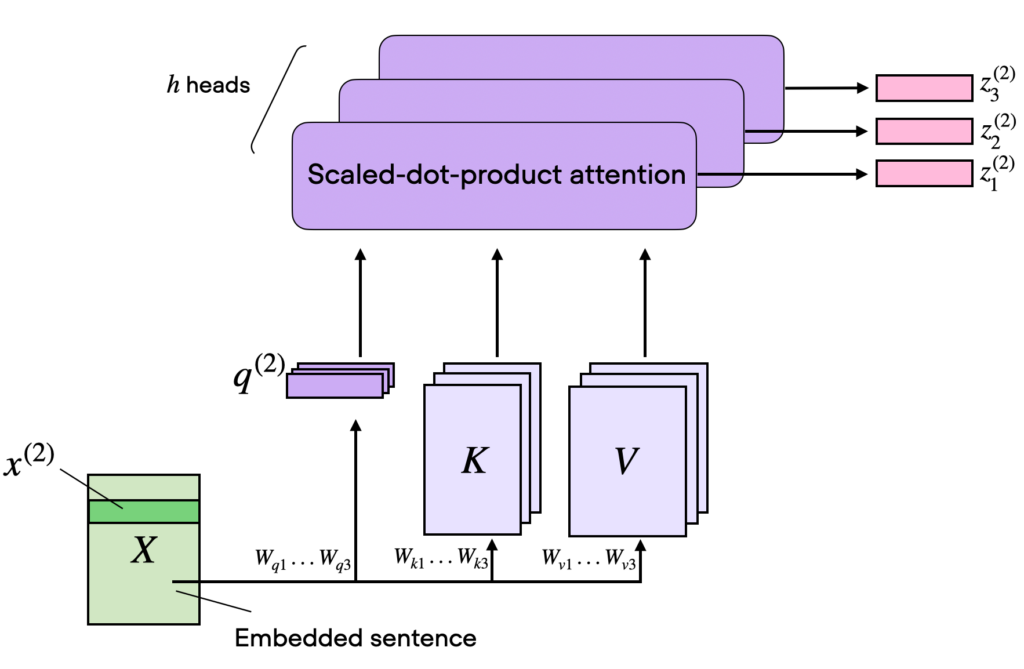
Multi-Head Attention
To capture different aspects of relationships between words, the Transformer employs multi-head attention. This involves running multiple self-attention operations in parallel, each with different sets of Q, K, and V vectors, and then concatenating their outputs. This approach allows the model to learn richer representations of the data.
Sebastian Raschka. (2024, 14 de enero). Understanding and Coding Self-Attention, Multi-Head Attention, Cross-Attention, and Causal-Attention in LLMs. https://magazine.sebastianraschka.com/p/understanding-and-coding-self-attention
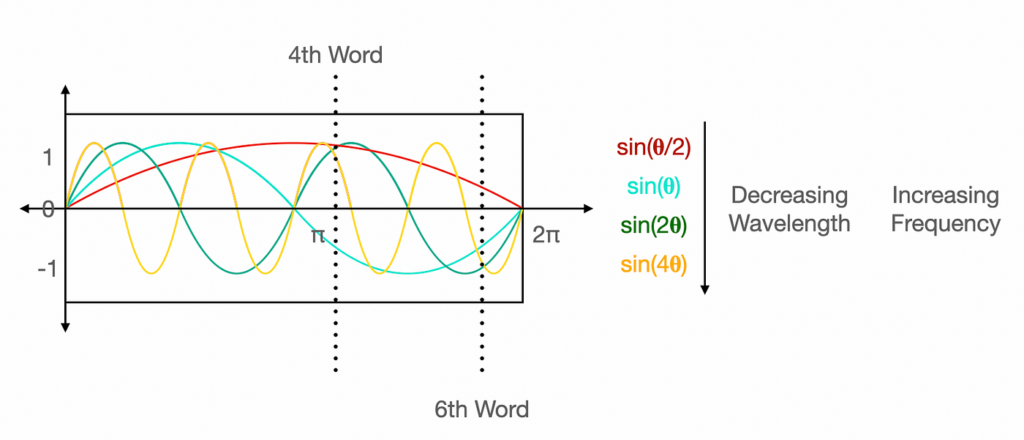
Positional Encoding
Unlike RNNs, Transformers do not have an inherent sense of order because they process the entire sequence at once. To retain the positional information of words, Transformers add positional encodings to the input embeddings. These encodings use sine and cosine functions to create unique patterns that represent each position in the sequence, enabling the model to understand word order.
Nikhil Verma. (2022, 28 de diciembre). Positional Encoding in Transformers. https://lih-verma.medium.com/positional-embeddings-in-transformer-eab35e5cb40d
Layer Normalization and Residual Connections
Transformers use layer normalization and residual connections to stabilize training and allow for deeper networks. Layer normalization standardizes the inputs to each layer, while residual connections add the input of a layer to its output, facilitating gradient flow and preventing the vanishing gradient problem.
The Impact of Transformers
Transformers have revolutionized NLP and beyond, offering several key advantages:
- Parallelization: Since Transformers process entire sequences simultaneously, they benefit from increased computational efficiency and faster training times.
- Scalability: Transformers scale well with data and computational resources, making them suitable for training large models on massive datasets.
- Versatility: Beyond NLP, Transformers have been successfully applied to various domains, including computer vision (e.g., Vision Transformers or ViTs), protein folding (e.g., AlphaFold), and even game playing.
Transformer-based Models
The success of the Transformer architecture has led to the development of several influential models:
- BERT (Bidirectional Encoder Representations from Transformers): BERT set new benchmarks for NLP tasks by pre-training on large corpora and fine-tuning for specific tasks.
- GPT (Generative Pre-trained Transformer): OpenAI’s GPT series, particularly GPT-3, demonstrated the power of large-scale language models in generating coherent and contextually relevant text.
- T5 (Text-to-Text Transfer Transformer): Google’s T5 reframed all NLP tasks as text-to-text problems, unifying various tasks under a single architecture.
Conclusion
The Transformer architecture has fundamentally changed the landscape of AI and NLP, providing a powerful framework for building models that understand and generate human language with remarkable accuracy. Its innovative use of self-attention mechanisms and ability to handle large-scale data have opened new frontiers in AI research and applications. As the field continues to evolve, the Transformer and its descendants will undoubtedly remain at the forefront of AI advancements.
Stay tuned to our blog for more insights into the latest developments in artificial intelligence and how these innovations are shaping our world.